
Abstract
This article describes a framework that allows construction of fully automated business web applications.
Project
Home Counselor Online is a customer relationship management system used by housing counselors. FannieMae offers it as a service mostly to nonprofit organizations. See a detailed Presentation of the HCO functionality. [UPDATE: 10/31/2019. HCO served thousands of home counselors across the United States for 18 years until it was replaced by a 3rd-party service. Fannie Mae Retires Home Counselor Online]
My assignment
I joined the HCO team in 2001, at the very beginning of the project. I proposed to the project manager that I would initially build scaffolding for the application: it would have a login screen, some preliminary version of the home page, one or two sample pages and a bunch of stubs for other developers to flesh out. That worked out well and in a few months we released the first version of HCO. It was based on Struts 1.0, JSP, Weblogic, had a couple of EJBs and used TOPLink for persistence.
Over the next two years we continued growing the application by adding more and more features.
Challenge
In those two years, just as expected, the application started growing out of control: developers were introducing different solutions to similar problems, screens started deviating from the standard look-and-feel, the amount of Java and JSP code mushroomed.
Coincidentally, at that point the business owners of the application decided to give it a facelift. We would have a whole new visual paradigm, developed for us by a third-party firm, CDG Interactive. The design proposed by CDG and accepted by the business owners of HCO had nothing in common with our current design. We were facing a rewrite of the entire front-end of the application. This gave us a fantastic opportunity to improve on the overall design of the app.
Solution
I proposed to my manager that I would develop a framework that would take the design created by CDG and automate it. Fortunately, their design was of great quality and highly consistent from screen to screen.
CDG used design patterns, for example the one I called editable list. In this pattern the top of the screen would display a list of entities of some kind (addresses, assets, liabilities, appointments, you-name-it). When you clicked on one of these entities, the screen would expand with an editable detail panel. There were a few other patterns as well.
My suggestion was to build automated support for those patterns and control the implementation by configuration captured mostly in JSP Custom Tags. We would not actually have to write much code, either Java or HTML, for each individual screen: instead we would configure an automated pattern to implement the screen. The automation would take care of both the front end and the back end. I captured these ideas in a presentation and showed it to the decision makers. My claim was that we would rewrite the entire application in 4 months and reduce its size at the same time. They said yes.
I wrote a framework, called DA for Different Architecture, consisting of controllers, form beans, HTML renderers and custom JSP tags. The framework took care of the CDG patterns as well all mundane tasks, including transaction handling, moving data between layers, validating the user input, handling security and most importantly generating almost all of HTML. All that was left to do was configure and customize individual screens. The plan worked out like a charm and version 4 was delivered on time as promised.
Consider this example. We needed a screen containing an editable list:
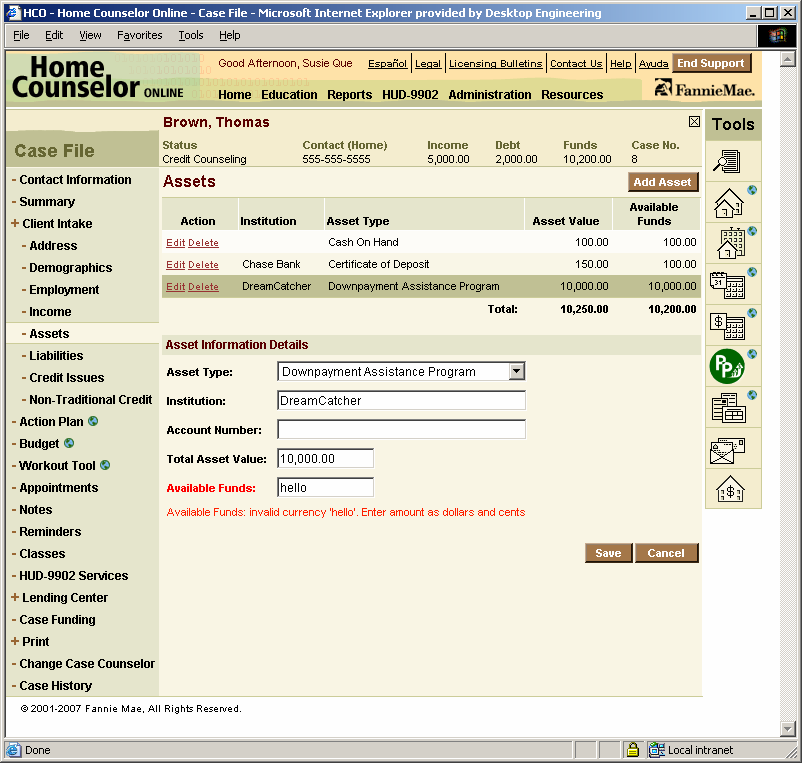
To implement this screen we created just two artifacts: a JSP and a FormBean class:
<%@ taglib uri="da.tld" prefix="da" %>
<da:editableList formBean="Assets" title="Assets"
emptyListMessage="No Asset information recorded.">
<da:action type="add" label="Add Asset" />
<da:rowAction type="edit" />
<da:rowAction type="delete" />
<da:column property="depositoryName" />
<da:column property="assetTypeCode" />
<da:column property="assetValueAmount"
label="Asset Value"
footerProperty="totalAssetValue" />
<da:column property="availableFundsAmount"
label="Available Funds"
footerProperty="totalAvailableFunds" />
<da:footer align="right">
Total:
</da:footer>
<da:detail title="Asset Information Details">
<da:input property="assetTypeCode" width="250px" />
<da:input property="depositoryName" width="250px" />
<da:input property="assetAccountNumber" width="250px" />
<da:input property="assetValueAmount" />
<da:input property="availableFundsAmount" />
<da:action type="save" />
<da:action type="cancel" />
</da:detail>
</da:editableList>
The Java implementation of the back-end follows. The CaseFile and Asset classes mentioned here are regular JavaBeans with no business logic in them and a small number of Annotations capturing field types, labels, ranges etc, when they differ from defaults. They are persisted by TOPLink.
package com.fanniemae.xo.web.casefile;
public class AssetEditableList extends EditableListForCaseFileElements
{
public AssetEditableList(CaseFileController controller) {
super(controller, Asset.class);
}
public List getList() {
return getCaseFile().getSortedAssets();
}
protected void saveNewBean(Asset bean) {
getCaseFile().addAsset(bean);
}
protected void deleteBean(int index) {
Asset asset = getRow(index);
getCaseFile().removeAsset(asset);
}
public void validate(
HttpServletRequest request,
ActionDescriptor action)
{
// Note: no format, range or other types of validations here
Asset asset = getDomainObject();
if(asset.getAssetValueAmount() < asset.getAvailableFundsAmount()) {
addValidationError("Available Funds amount "
+ "cannot be greater than the Asset Value.");
}
}
@Type(Type.MONEY)
public double getTotalAssetValue() {
return getCaseFile().getTotalAssetValueAmount();
}
@Type(Type.MONEY)
public double getTotalAvailableFunds() {
return getCaseFile().getTotalAvailableFundsAmount();
}
public String save(
HttpServletRequest request,
HttpServletResponse response)
{
getCaseFile().updateAssetTotals();
return super.save(request, response);
}
}In 2005 I expanded the framework to produce canned reports in the same manner. You would just describe contents of the report and the framework would take care of all formatting etc. automatically. See a report definition and sample report.
I anticipated that some other applications might benefit from this approach, so I made the whole framework skin-based. This means that the particular look of the screens and reports was determined by a set of classes, which could be replaced entirely or partially. And sure enough, another application came along. We created a new skin based on the one used in HCO, yet somewhat different, and wrote another application in the same manner using the DA framework.
Mistakes were made
When Jack Tran interviewed me for this job, the entire interview lasted just a few minutes. He showed me a draft specification of the system and asked: "Can you write an app like this?" I gave him a confident yes. The reality is that I had very little idea of how to write a web app. From my previous job at Inline Software, I had learned a specific set of solutions, such as EJB, which were actively pushed by Sun Microsystems at the time. It took years for me to realize that EJB just added an entirely unnecessary layer of complexity. It's much easier and more efficient for servlets to talk to the database directly.
The template-based design was a clear success. At the same there was one specific aspect of that project that was an embarrassing epic fail. I designed the application to be stateful: there was a server-side HttpSession maintained for every user. This design produced a variety of problems:
- The application could not scale as the number of users grew: every user session needed a certain amount of RAM bound for the duration of the session. Fannie Mae owned its servers, a very limited number of those.
- MORE IMPORTANTLY: we used a global load balancer. The load balancer would randomly direct traffic to different servers. The user would open a session and start working on a case. In 40 minutes the DNS resolution for the server would expire in the browser, the browser would go back to the DNS server to resolve the domain. The DNS server is where the load balancer resided. It would return the IP address of a randomly chosen server. So the next HTTP request would most of the time arrive at a different server. This new server did not have the user's session, so it would fail the request as unauthenticated. The user had to log in again and then redo the latest data entry.
At the time I "solved" the problem by including a session token in every post. When a server received a request, it would first look at the session token. The session token contained the identity of the server that hosted the session. The server receiving the request would then forward it to the server that owned the session. This "solution" kind-of worked, but had two major flaws:
- It defeated load balancing. Instead of evenly distributing load on servers, we would now have all servers doing the additional work of forwarding requests to each other.
- MORE IMPORTANTLY: if one of the servers crashed, the other servers would still continue trying to forward requests to it. As a result, those other servers would see an increase in the rate of failures and they would get restarted by the automation. As a result, one failed server would take down the entire web app for all users in a matter of minutes. This actually happened several times. With a bit of hacking, we "fixed" the issue: we would detect this type of failure and gracefully recover.
Lesson learned: load-balanced servers must not have any dependencies on each other. For that, the application must be stateless. All user state should be either stored in the database, or get shuttled back end forth in every request.